PostgreSQL 语法
默认情况下 PostgreSQL 安装完成后,自带了一个命令行工具 SQL Shell(psql)。
Linux 系统可以直接切换到 postgres 用户来开启命令行工具:
# sudo -i -u postgres
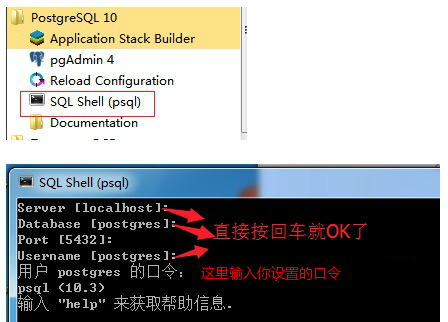
Windows 系统一般在它的安装目录下:
Program Files → PostgreSQL 11.3 → SQL Shell(psql)
Mac OS 我们直接搜索就可以了找到:
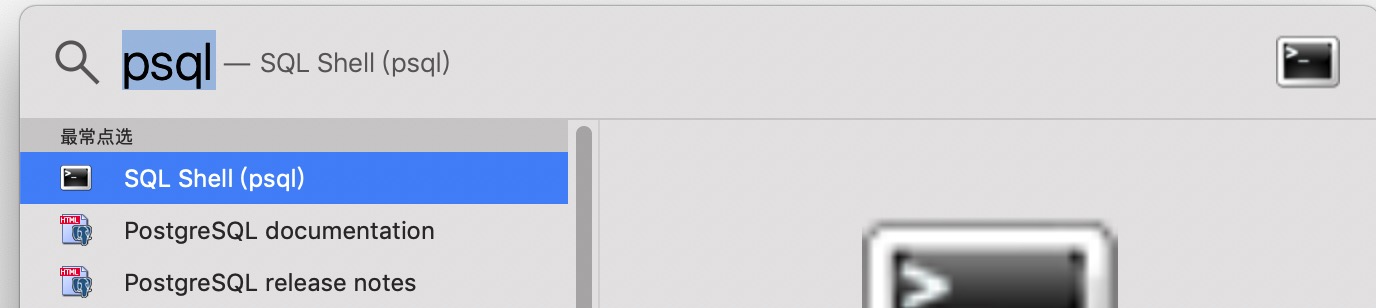
进入命令行工具,我们可以使用 \help 来查看各个命令的语法 :
postgres-# \help <command_name>
例如,我们查看下 select 语句的语法:
postgres=# \help SELECT
Command: SELECT
Description: retrieve rows from a table or view
Syntax:
[ WITH [ RECURSIVE ] with_query [, ...] ]
SELECT [ ALL | DISTINCT [ ON ( expression [, ...] ) ] ]
[ * | expression [ [ AS ] output_name ] [, ...] ]
[ FROM from_item [, ...] ]
[ WHERE condition ]
[ GROUP BY grouping_element [, ...] ]
[ HAVING condition [, ...] ]
[ WINDOW window_name AS ( window_definition ) [, ...] ]
[ { UNION | INTERSECT | EXCEPT } [ ALL | DISTINCT ] select ]
[ ORDER BY expression [ ASC | DESC | USING operator ] [ NULLS { FIRST | LAST } ] [, ...] ]
[ LIMIT { count | ALL } ]
[ OFFSET start [ ROW | ROWS ] ]
[ FETCH { FIRST | NEXT } [ count ] { ROW | ROWS } ONLY ]
[ FOR { UPDATE | NO KEY UPDATE | SHARE | KEY SHARE } [ OF table_name [, ...] ] [ NOWAIT | SKIP LOCKED ] [...] ]
from_item 可以是以下选项之一:
[ ONLY ] table_name [ * ] [ [ AS ] alias [ ( column_alias [, ...] ) ] ]
SQL 语句
一个 SQL 语句通常包含了关键字、标识符(字段)、常量、特殊符号等,下面是一个简单的 SQL 语句:
SELECT id, name FROM runoob
|
SELECT |
id, name |
FROM |
runoob |
| 符号类型 |
关键字 |
标识符(字段) |
关键字 |
标识符 |
| 描述 |
命令 |
id 和 name 字段 |
语句,用于设置条件规则等 |
表名 |
PostgreSQL 命令
ABORT
ABORT 用于退出当前事务。
ABORT [ WORK | TRANSACTION ]
ALTER AGGREGATE
修改一个聚集函数的定义 。
ALTER AGGREGATE _name_ ( _argtype_ [ , ... ] ) RENAME TO _new_name_
ALTER AGGREGATE _name_ ( _argtype_ [ , ... ] ) OWNER TO _new_owner_
ALTER AGGREGATE _name_ ( _argtype_ [ , ... ] ) SET SCHEMA _new_schema_
ALTER COLLATION
修改一个排序规则定义 。
ALTER COLLATION _name_ RENAME TO _new_name_
ALTER COLLATION _name_ OWNER TO _new_owner_
ALTER COLLATION _name_ SET SCHEMA _new_schema_
ALTER CONVERSION
修改一个编码转换的定义。
ALTER CONVERSION name RENAME TO new_name
ALTER CONVERSION name OWNER TO new_owner
ALTER DATABASE
修改一个数据库。
ALTER DATABASE name SET parameter { TO | = } { value | DEFAULT }
ALTER DATABASE name RESET parameter
ALTER DATABASE name RENAME TO new_name
ALTER DATABASE name OWNER TO new_owner
ALTER DEFAULT PRIVILEGES
定义默认的访问权限。
ALTER DEFAULT PRIVILEGES
[ FOR { ROLE | USER } target_role [, ...] ]
[ IN SCHEMA schema_name [, ...] ]
abbreviated_grant_or_revoke
where abbreviated_grant_or_revoke is one of:
GRANT { { SELECT | INSERT | UPDATE | DELETE | TRUNCATE | REFERENCES | TRIGGER }
[, ...] | ALL [ PRIVILEGES ] }
ON TABLES
TO { [ GROUP ] role_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]
...
ALTER DOMAIN
修改一个域的定义。
ALTER DOMAIN name { SET DEFAULT expression | DROP DEFAULT }
ALTER DOMAIN name { SET | DROP } NOT NULL
ALTER DOMAIN name ADD domain_constraint
ALTER DOMAIN name DROP CONSTRAINT constraint_name [ RESTRICT | CASCADE ]
ALTER DOMAIN name OWNER TO new_owner
ALTER FUNCTION
修改一个函数的定义。
ALTER FUNCTION name ( [ type [, ...] ] ) RENAME TO new_name
ALTER FUNCTION name ( [ type [, ...] ] ) OWNER TO new_owner
ALTER GROUP
修改一个用户组。
ALTER GROUP groupname ADD USER username [, ... ]
ALTER GROUP groupname DROP USER username [, ... ]
ALTER GROUP groupname RENAME TO new_name
ALTER INDEX
修改一个索引的定义。
ALTER INDEX name OWNER TO new_owner
ALTER INDEX name SET TABLESPACE indexspace_name
ALTER INDEX name RENAME TO new_name
ALTER LANGUAGE
修改一个过程语言的定义。
ALTER LANGUAGE name RENAME TO new_name
ALTER OPERATOR
改变一个操作符的定义。
ALTER OPERATOR name ( { lefttype | NONE }, { righttype | NONE } )
OWNER TO new_owner
ALTER OPERATOR CLASS
修改一个操作符表的定义。
ALTER OPERATOR CLASS name USING index_method RENAME TO new_name
ALTER OPERATOR CLASS name USING index_method OWNER TO new_owner
ALTER SCHEMA
修改一个模式的定义。
ALTER SCHEMA name RENAME TO new_name
ALTER SCHEMA name OWNER TO new_owner
ALTER SEQUENCE
修改一个序列生成器的定义。
ALTER SEQUENCE name [ INCREMENT [ BY ] increment ]
[ MINVALUE minvalue | NO MINVALUE ]
[ MAXVALUE maxvalue | NO MAXVALUE ]
[ RESTART [ WITH ] start ] [ CACHE cache ] [ [ NO ] CYCLE ]
ALTER TABLE
修改表的定义。
ALTER TABLE [ ONLY ] name [ * ]
action [, ... ]
ALTER TABLE [ ONLY ] name [ * ]
RENAME [ COLUMN ] column TO new_column
ALTER TABLE name
RENAME TO new_name
其中 action 可以是以选项之一:
ADD [ COLUMN ] column_type [ column_constraint [ ... ] ]
DROP [ COLUMN ] column [ RESTRICT | CASCADE ]
ALTER [ COLUMN ] column TYPE type [ USING expression ]
ALTER [ COLUMN ] column SET DEFAULT expression
ALTER [ COLUMN ] column DROP DEFAULT
ALTER [ COLUMN ] column { SET | DROP } NOT NULL
ALTER [ COLUMN ] column SET STATISTICS integer
ALTER [ COLUMN ] column SET STORAGE { PLAIN | EXTERNAL | EXTENDED | MAIN }
ADD table_constraint
DROP CONSTRAINT constraint_name [ RESTRICT | CASCADE ]
CLUSTER ON index_name
SET WITHOUT CLUSTER
SET WITHOUT OIDS
OWNER TO new_owner
SET TABLESPACE tablespace_name
ALTER TABLESPACE
修改一个表空间的定义。
ALTER TABLESPACE name RENAME TO new_name
ALTER TABLESPACE name OWNER TO new_owner
ALTER TRIGGER
修改改变一个触发器的定义 。
ALTER TRIGGER name ON table RENAME TO new_name
ALTER TYPE
修改一个类型的定义 。
ALTER TYPE name OWNER TO new_owner
ALTER USER
修改数据库用户帐号 。
ALTER USER name [ [ WITH ] option [ ... ] ]
ALTER USER name RENAME TO new_name
ALTER USER name SET parameter { TO | = } { value | DEFAULT }
ALTER USER name RESET parameter
Where option can be −
[ ENCRYPTED | UNENCRYPTED ] PASSWORD 'password'
| CREATEDB | NOCREATEDB
| CREATEUSER | NOCREATEUSER
| VALID UNTIL 'abstime'
ANALYZE
收集与数据库有关的统计。
ANALYZE [ VERBOSE ] [ table [ (column [, ...] ) ] ]
BEGIN
开始一个事务块。
BEGIN [ WORK | TRANSACTION ] [ transaction_mode [, ...] ]
transaction_mode 可以是以下选项之一:
ISOLATION LEVEL {
SERIALIZABLE | REPEATABLE READ | READ COMMITTED
| READ UNCOMMITTED
}
READ WRITE | READ ONLY
CHECKPOINT
强制一个事务日志检查点 。
CHECKPOINT
CLOSE
关闭游标。
CLOSE name
CLUSTER
根据一个索引对某个表盘簇化排序。
CLUSTER index_name ON table_name
CLUSTER table_name
CLUSTER
COMMENT
定义或者改变一个对象的注释。
COMMENT ON {
TABLE object_name |
COLUMN table_name.column_name |
AGGREGATE agg_name (agg_type) |
CAST (source_type AS target_type) |
CONSTRAINT constraint_name ON table_name |
CONVERSION object_name |
DATABASE object_name |
DOMAIN object_name |
FUNCTION func_name (arg1_type, arg2_type, ...) |
INDEX object_name |
LARGE OBJECT large_object_oid |
OPERATOR op (left_operand_type, right_operand_type) |
OPERATOR CLASS object_name USING index_method |
[ PROCEDURAL ] LANGUAGE object_name |
RULE rule_name ON table_name |
SCHEMA object_name |
SEQUENCE object_name |
TRIGGER trigger_name ON table_name |
TYPE object_name |
VIEW object_name
}
IS 'text'
COMMIT
提交当前事务。
COMMIT [ WORK | TRANSACTION ]
COPY
在表和文件之间拷贝数据。
COPY table_name [ ( column [, ...] ) ]
FROM { 'filename' | STDIN }
[ WITH ]
[ BINARY ]
[ OIDS ]
[ DELIMITER [ AS ] 'delimiter' ]
[ NULL [ AS ] 'null string' ]
[ CSV [ QUOTE [ AS ] 'quote' ]
[ ESCAPE [ AS ] 'escape' ]
[ FORCE NOT NULL column [, ...] ]
COPY table_name [ ( column [, ...] ) ]
TO { 'filename' | STDOUT }
[ [ WITH ]
[ BINARY ]
[ OIDS ]
[ DELIMITER [ AS ] 'delimiter' ]
[ NULL [ AS ] 'null string' ]
[ CSV [ QUOTE [ AS ] 'quote' ]
[ ESCAPE [ AS ] 'escape' ]
[ FORCE QUOTE column [, ...] ]
CREATE AGGREGATE
定义一个新的聚集函数。
CREATE AGGREGATE name (
BASETYPE = input_data_type,
SFUNC = sfunc,
STYPE = state_data_type
[, FINALFUNC = ffunc ]
[, INITCOND = initial_condition ]
)
CREATE CAST
定义一个用户定义的转换。
CREATE CAST (source_type AS target_type)
WITH FUNCTION func_name (arg_types)
[ AS ASSIGNMENT | AS IMPLICIT ]
CREATE CAST (source_type AS target_type)
WITHOUT FUNCTION
[ AS ASSIGNMENT | AS IMPLICIT ]
CREATE CONSTRAINT TRIGGER
定义一个新的约束触发器 。
CREATE CONSTRAINT TRIGGER name
AFTER events ON
table_name constraint attributes
FOR EACH ROW EXECUTE PROCEDURE func_name ( args )
CREATE CONVERSION
定义一个新的的编码转换。
CREATE [DEFAULT] CONVERSION name
FOR source_encoding TO dest_encoding FROM func_name
CREATE DATABASE
创建新数据库。
CREATE DATABASE name
[ [ WITH ] [ OWNER [=] db_owner ]
[ TEMPLATE [=] template ]
[ ENCODING [=] encoding ]
[ TABLESPACE [=] tablespace ]
]
CREATE DOMAIN
定义一个新域。
CREATE DOMAIN name [AS] data_type
[ DEFAULT expression ]
[ constraint [ ... ] ]
constraint 可以是以下选项之一:
[ CONSTRAINT constraint_name ]
{ NOT NULL | NULL | CHECK (expression) }
CREATE FUNCTION
定义一个新函数。
CREATE [ OR REPLACE ] FUNCTION name ( [ [ arg_name ] arg_type [, ...] ] )
RETURNS ret_type
{ LANGUAGE lang_name
| IMMUTABLE | STABLE | VOLATILE
| CALLED ON NULL INPUT | RETURNS NULL ON NULL INPUT | STRICT
| [ EXTERNAL ] SECURITY INVOKER | [ EXTERNAL ] SECURITY DEFINER
| AS 'definition'
| AS 'obj_file', 'link_symbol'
} ...
[ WITH ( attribute [, ...] ) ]
CREATE GROUP
定义一个新的用户组。
CREATE GROUP name [ [ WITH ] option [ ... ] ]
Where option can be:
SYSID gid
| USER username [, ...]
CREATE INDEX
定义一个新索引。
CREATE [ UNIQUE ] INDEX name ON table [ USING method ]
( { column | ( expression ) } [ opclass ] [, ...] )
[ TABLESPACE tablespace ]
[ WHERE predicate ]
CREATE LANGUAGE
定义一种新的过程语言。
CREATE [ TRUSTED ] [ PROCEDURAL ] LANGUAGE name
HANDLER call_handler [ VALIDATOR val_function ]
CREATE OPERATOR
定义一个新的操作符。
CREATE OPERATOR name (
PROCEDURE = func_name
[, LEFTARG = left_type ] [, RIGHTARG = right_type ]
[, COMMUTATOR = com_op ] [, NEGATOR = neg_op ]
[, RESTRICT = res_proc ] [, JOIN = join_proc ]
[, HASHES ] [, MERGES ]
[, SORT1 = left_sort_op ] [, SORT2 = right_sort_op ]
[, LTCMP = less_than_op ] [, GTCMP = greater_than_op ]
)
CREATE OPERATOR CLASS
定义一个新的操作符表。
CREATE OPERATOR CLASS name [ DEFAULT ] FOR TYPE data_type
USING index_method AS
{ OPERATOR strategy_number operator_name [ ( op_type, op_type ) ] [ RECHECK ]
| FUNCTION support_number func_name ( argument_type [, ...] )
| STORAGE storage_type
} [, ... ]
CREATE ROLE
定义一个新的数据库角色。
CREATE ROLE _name_ [ [ WITH ] _option_ [ ... ] ]
where `_option_` can be:
SUPERUSER | NOSUPERUSER
| CREATEDB | NOCREATEDB
| CREATEROLE | NOCREATEROLE
...
CREATE RULE
定义一个新重写规则。
CREATE [ OR REPLACE ] RULE name AS ON event
TO table [ WHERE condition ]
DO [ ALSO | INSTEAD ] { NOTHING | command | ( command ; command ... ) }
CREATE SCHEMA
定义一个新模式。
CREATE SCHEMA schema_name
[ AUTHORIZATION username ] [ schema_element [ ... ] ]
CREATE SCHEMA AUTHORIZATION username
[ schema_element [ ... ] ]
CREATE SERVER
定义一个新的外部服务器。。
CREATE SERVER _server_name_ [ TYPE '_server_type_' ] [ VERSION '_server_version_' ]
FOREIGN DATA WRAPPER _fdw_name_
[ OPTIONS ( _option_ '_value_' [, ... ] ) ]
CREATE SEQUENCE
定义一个新序列发生器。
CREATE [ TEMPORARY | TEMP ] SEQUENCE name
[ INCREMENT [ BY ] increment ]
[ MINVALUE minvalue | NO MINVALUE ]
[ MAXVALUE maxvalue | NO MAXVALUE ]
[ START [ WITH ] start ] [ CACHE cache ] [ [ NO ] CYCLE ]
CREATE TABLE
定义一个新表。
CREATE [ [ GLOBAL | LOCAL ] {
TEMPORARY | TEMP } ] TABLE table_name ( {
column_name data_type [ DEFAULT default_expr ] [ column_constraint [ ... ] ]
| table_constraint
| LIKE parent_table [ { INCLUDING | EXCLUDING } DEFAULTS ]
} [, ... ]
)
[ INHERITS ( parent_table [, ... ] ) ]
[ WITH OIDS | WITHOUT OIDS ]
[ ON COMMIT { PRESERVE ROWS | DELETE ROWS | DROP } ]
[ TABLESPACE tablespace ]
column_constraint 可以是以下选项之一:
[ CONSTRAINT constraint_name ] {
NOT NULL |
NULL |
UNIQUE [ USING INDEX TABLESPACE tablespace ] |
PRIMARY KEY [ USING INDEX TABLESPACE tablespace ] |
CHECK (expression) |
REFERENCES ref_table [ ( ref_column ) ]
[ MATCH FULL | MATCH PARTIAL | MATCH SIMPLE ]
[ ON DELETE action ] [ ON UPDATE action ]
}
[ DEFERRABLE | NOT DEFERRABLE ] [ INITIALLY DEFERRED | INITIALLY IMMEDIATE ]
table_constraint 可以是以下选项之一:
[ CONSTRAINT constraint_name ]
{ UNIQUE ( column_name [, ... ] ) [ USING INDEX TABLESPACE tablespace ] |
PRIMARY KEY ( column_name [, ... ] ) [ USING INDEX TABLESPACE tablespace ] |
CHECK ( expression ) |
FOREIGN KEY ( column_name [, ... ] )
REFERENCES ref_table [ ( ref_column [, ... ] ) ]
[ MATCH FULL | MATCH PARTIAL | MATCH SIMPLE ]
[ ON DELETE action ] [ ON UPDATE action ] }
[ DEFERRABLE | NOT DEFERRABLE ] [ INITIALLY DEFERRED | INITIALLY IMMEDIATE ]
CREATE TABLE AS
从一条查询的结果中定义一个新表。
CREATE [ [ GLOBAL | LOCAL ] { TEMPORARY | TEMP } ] TABLE table_name
[ (column_name [, ...] ) ] [ [ WITH | WITHOUT ] OIDS ]
AS query
CREATE TABLESPACE
定义一个新的表空间。
CREATE TABLESPACE tablespace_name [ OWNER username ] LOCATION 'directory'
CREATE TRIGGER
定义一个新的触发器。
CREATE TRIGGER name { BEFORE | AFTER } { event [ OR ... ] }
ON table [ FOR [ EACH ] { ROW | STATEMENT } ]
EXECUTE PROCEDURE func_name ( arguments )
CREATE TYPE
定义一个新的数据类型。
CREATE TYPE name AS
( attribute_name data_type [, ... ] )
CREATE TYPE name (
INPUT = input_function,
OUTPUT = output_function
[, RECEIVE = receive_function ]
[, SEND = send_function ]
[, ANALYZE = analyze_function ]
[, INTERNALLENGTH = { internal_length | VARIABLE } ]
[, PASSEDBYVALUE ]
[, ALIGNMENT = alignment ]
[, STORAGE = storage ]
[, DEFAULT = default ]
[, ELEMENT = element ]
[, DELIMITER = delimiter ]
)
CREATE USER
创建一个新的数据库用户帐户。
CREATE USER name [ [ WITH ] option [ ... ] ]
option 可以是以下选项之一:
SYSID uid
| [ ENCRYPTED | UNENCRYPTED ] PASSWORD 'password'
| CREATEDB | NOCREATEDB
| CREATEUSER | NOCREATEUSER
| IN GROUP group_name [, ...]
| VALID UNTIL 'abs_time'
CREATE VIEW
定义一个视图。
CREATE [ OR REPLACE ] VIEW name [ ( column_name [, ...] ) ] AS query
DEALLOCATE
删除一个准备好的查询。
DEALLOCATE [ PREPARE ] plan_name
DECLARE
定义一个游标。
DECLARE name [ BINARY ] [ INSENSITIVE ] [ [ NO ] SCROLL ]
CURSOR [ { WITH | WITHOUT } HOLD ] FOR query
[ FOR { READ ONLY | UPDATE [ OF column [, ...] ] } ]
DELETE
删除一个表中的行。
DELETE FROM [ ONLY ] table [ WHERE condition ]
DROP AGGREGATE
删除一个用户定义的聚集函数。
DROP AGGREGATE name ( type ) [ CASCADE | RESTRICT ]
DROP CAST
删除一个用户定义的类型转换。
DROP CAST (source_type AS target_type) [ CASCADE | RESTRICT ]
DROP CONVERSION
删除一个用户定义的编码转换。
DROP CONVERSION name [ CASCADE | RESTRICT ]
DROP DATABASE
删除一个数据库。
DROP DATABASE name
DROP DOMAIN
删除一个用户定义的域。
DROP DOMAIN name [, ...] [ CASCADE | RESTRICT ]
DROP FUNCTION
删除一个函数。
DROP FUNCTION name ( [ type [, ...] ] ) [ CASCADE | RESTRICT ]
DROP GROUP
删除一个用户组。
DROP GROUP name
DROP INDEX
删除一个索引。
DROP INDEX name [, ...] [ CASCADE | RESTRICT ]
DROP LANGUAGE
删除一个过程语言。
DROP [ PROCEDURAL ] LANGUAGE name [ CASCADE | RESTRICT ]
DROP OPERATOR
删除一个操作符。
DROP OPERATOR name ( { left_type | NONE }, { right_type | NONE } )
[ CASCADE | RESTRICT ]
DROP OPERATOR CLASS
删除一个操作符表。
DROP OPERATOR CLASS name USING index_method [ CASCADE | RESTRICT ]
DROP ROLE
删除一个数据库角色。
DROP ROLE [ IF EXISTS ] _name_ [, ...]
DROP RULE
删除一个重写规则。
DROP RULE name ON relation [ CASCADE | RESTRICT ]
DROP SCHEMA
删除一个模式。
DROP SCHEMA name [, ...] [ CASCADE | RESTRICT ]
DROP SEQUENCE
删除一个序列。
DROP SEQUENCE name [, ...] [ CASCADE | RESTRICT ]
DROP TABLE
删除一个表。
DROP TABLE name [, ...] [ CASCADE | RESTRICT ]
DROP TABLESPACE
删除一个表空间。
DROP TABLESPACE tablespace_name
DROP TRIGGER
删除一个触发器定义。
DROP TRIGGER name ON table [ CASCADE | RESTRICT ]
DROP TYPE
删除一个用户定义数据类型。
DROP TYPE name [, ...] [ CASCADE | RESTRICT ]
DROP USER
删除一个数据库用户帐号。
DROP USER name
DROP VIEW
删除一个视图。
DROP VIEW name [, ...] [ CASCADE | RESTRICT ]
END
提交当前的事务。
END [ WORK | TRANSACTION ]
EXECUTE
执行一个准备好的查询。
EXECUTE plan_name [ (parameter [, ...] ) ]
EXPLAIN
显示一个语句的执行规划。
EXPLAIN [ ANALYZE ] [ VERBOSE ] statement
FETCH
用游标从查询中抓取行。
FETCH [ direction { FROM | IN } ] cursor_name
direction 可以是以下选项之一:
NEXT
PRIOR
FIRST
LAST
ABSOLUTE count
RELATIVE count
count
ALL
FORWARD
FORWARD count
FORWARD ALL
BACKWARD
BACKWARD count
BACKWARD ALL
GRANT
定义访问权限。
GRANT { { SELECT | INSERT | UPDATE | DELETE | RULE | REFERENCES | TRIGGER }
[,...] | ALL [ PRIVILEGES ] }
ON [ TABLE ] table_name [, ...]
TO { username | GROUP group_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]
GRANT { { CREATE | TEMPORARY | TEMP } [,...] | ALL [ PRIVILEGES ] }
ON DATABASE db_name [, ...]
TO { username | GROUP group_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]
GRANT { CREATE | ALL [ PRIVILEGES ] }
ON TABLESPACE tablespace_name [, ...]
TO { username | GROUP group_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]
GRANT { EXECUTE | ALL [ PRIVILEGES ] }
ON FUNCTION func_name ([type, ...]) [, ...]
TO { username | GROUP group_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]
GRANT { USAGE | ALL [ PRIVILEGES ] }
ON LANGUAGE lang_name [, ...]
TO { username | GROUP group_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]
GRANT { { CREATE | USAGE } [,...] | ALL [ PRIVILEGES ] }
ON SCHEMA schema_name [, ...]
TO { username | GROUP group_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]
INSERT
在表中创建新行,即插入数据。
INSERT INTO table [ ( column [, ...] ) ]
{ DEFAULT VALUES | VALUES ( { expression | DEFAULT } [, ...] ) | query }
LISTEN
监听一个通知。
LISTEN name
LOAD
加载或重载一个共享库文件。
LOAD 'filename'
LOCK
锁定一个表。
LOCK [ TABLE ] name [, ...] [ IN lock_mode MODE ] [ NOWAIT ]
lock_mode 可以是以下选项之一:
ACCESS SHARE | ROW SHARE | ROW EXCLUSIVE | SHARE UPDATE EXCLUSIVE
| SHARE | SHARE ROW EXCLUSIVE | EXCLUSIVE | ACCESS EXCLUSIVE
MOVE
定位一个游标。
MOVE [ direction { FROM | IN } ] cursor_name
NOTIFY
生成一个通知。
NOTIFY name
PREPARE
创建一个准备好的查询。
PREPARE plan_name [ (data_type [, ...] ) ] AS statement
REINDEX
重建索引。
REINDEX { DATABASE | TABLE | INDEX } name [ FORCE ]
RELEASE SAVEPOINT
删除一个前面定义的保存点。
RELEASE [ SAVEPOINT ] savepoint_name
RESET
把一个运行时参数值恢复为默认值。
RESET name
RESET ALL
REVOKE
删除访问权限。
REVOKE [ GRANT OPTION FOR ]
{ { SELECT | INSERT | UPDATE | DELETE | RULE | REFERENCES | TRIGGER }
[,...] | ALL [ PRIVILEGES ] }
ON [ TABLE ] table_name [, ...]
FROM { username | GROUP group_name | PUBLIC } [, ...]
[ CASCADE | RESTRICT ]
REVOKE [ GRANT OPTION FOR ]
{ { CREATE | TEMPORARY | TEMP } [,...] | ALL [ PRIVILEGES ] }
ON DATABASE db_name [, ...]
FROM { username | GROUP group_name | PUBLIC } [, ...]
[ CASCADE | RESTRICT ]
REVOKE [ GRANT OPTION FOR ]
{ CREATE | ALL [ PRIVILEGES ] }
ON TABLESPACE tablespace_name [, ...]
FROM { username | GROUP group_name | PUBLIC } [, ...]
[ CASCADE | RESTRICT ]
REVOKE [ GRANT OPTION FOR ]
{ EXECUTE | ALL [ PRIVILEGES ] }
ON FUNCTION func_name ([type, ...]) [, ...]
FROM { username | GROUP group_name | PUBLIC } [, ...]
[ CASCADE | RESTRICT ]
REVOKE [ GRANT OPTION FOR ]
{ USAGE | ALL [ PRIVILEGES ] }
ON LANGUAGE lang_name [, ...]
FROM { username | GROUP group_name | PUBLIC } [, ...]
[ CASCADE | RESTRICT ]
REVOKE [ GRANT OPTION FOR ]
{ { CREATE | USAGE } [,...] | ALL [ PRIVILEGES ] }
ON SCHEMA schema_name [, ...]
FROM { username | GROUP group_name | PUBLIC } [, ...]
[ CASCADE | RESTRICT ]
ROLLBACK
退出当前事务。
ROLLBACK [ WORK | TRANSACTION ]
ROLLBACK TO SAVEPOINT
回滚到一个保存点。
ROLLBACK [ WORK | TRANSACTION ] TO [ SAVEPOINT ] savepoint_name
SAVEPOINT
在当前事务里定义一个新的保存点。
SAVEPOINT savepoint_name
SELECT
从表或视图中取出若干行。
SELECT [ ALL | DISTINCT [ ON ( expression [, ...] ) ] ]
* | expression [ AS output_name ] [, ...]
[ FROM from_item [, ...] ]
[ WHERE condition ]
[ GROUP BY expression [, ...] ]
[ HAVING condition [, ...] ]
[ { UNION | INTERSECT | EXCEPT } [ ALL ] select ]
[ ORDER BY expression [ ASC | DESC | USING operator ] [, ...] ]
[ LIMIT { count | ALL } ]
[ OFFSET start ]
[ FOR UPDATE [ OF table_name [, ...] ] ]
from_item 可以是以下选项:
[ ONLY ] table_name [ * ] [ [ AS ] alias [ ( column_alias [, ...] ) ] ]
( select ) [ AS ] alias [ ( column_alias [, ...] ) ]
function_name ( [ argument [, ...] ] )
[ AS ] alias [ ( column_alias [, ...] | column_definition [, ...] ) ]
function_name ( [ argument [, ...] ] ) AS ( column_definition [, ...] )
from_item [ NATURAL ] join_type from_item
[ ON join_condition | USING ( join_column [, ...] ) ]
SELECT INTO
从一个查询的结果中定义一个新表。
SELECT [ ALL | DISTINCT [ ON ( expression [, ...] ) ] ]
* | expression [ AS output_name ] [, ...]
INTO [ TEMPORARY | TEMP ] [ TABLE ] new_table
[ FROM from_item [, ...] ]
[ WHERE condition ]
[ GROUP BY expression [, ...] ]
[ HAVING condition [, ...] ]
[ { UNION | INTERSECT | EXCEPT } [ ALL ] select ]
[ ORDER BY expression [ ASC | DESC | USING operator ] [, ...] ]
[ LIMIT { count | ALL } ]
[ OFFSET start ]
[ FOR UPDATE [ OF table_name [, ...] ] ]
SET
修改运行时参数。
SET [ SESSION | LOCAL ] name { TO | = } { value | 'value' | DEFAULT }
SET [ SESSION | LOCAL ] TIME ZONE { time_zone | LOCAL | DEFAULT }
SET CONSTRAINTS
设置当前事务的约束检查模式。
SET CONSTRAINTS { ALL | name [, ...] } { DEFERRED | IMMEDIATE }
SET SESSION AUTHORIZATION
为当前会话设置会话用户标识符和当前用户标识符。
SET [ SESSION | LOCAL ] SESSION AUTHORIZATION username
SET [ SESSION | LOCAL ] SESSION AUTHORIZATION DEFAULT
RESET SESSION AUTHORIZATION
SET TRANSACTION
开始一个事务块。
SET TRANSACTION transaction_mode [, ...]
SET SESSION CHARACTERISTICS AS TRANSACTION transaction_mode [, ...]
Where transaction_mode is one of −
ISOLATION LEVEL { SERIALIZABLE | REPEATABLE READ | READ COMMITTED
| READ UNCOMMITTED }
READ WRITE | READ ONLY
SHOW
显示运行时参数的值。
SHOW name
SHOW ALL
START TRANSACTION
开始一个事务块。
START TRANSACTION [ transaction_mode [, ...] ]
transaction_mode 可以是下面的选项之一:
ISOLATION LEVEL { SERIALIZABLE | REPEATABLE READ | READ COMMITTED
| READ UNCOMMITTED }
READ WRITE | READ ONLY
TRUNCATE
清空一个或一组表。
TRUNCATE [ TABLE ] name
UNLISTEN
停止监听通知信息。
UNLISTEN { name | * }
UPDATE
更新一个表中的行。
UPDATE [ ONLY ] table SET column = { expression | DEFAULT } [, ...]
[ FROM from_list ]
[ WHERE condition ]
VACUUM
垃圾收集以及可选地分析一个数据库。
VACUUM [ FULL ] [ FREEZE ] [ VERBOSE ] [ table ]
VACUUM [ FULL ] [ FREEZE ] [ VERBOSE ] ANALYZE [ table [ (column [, ...] ) ] ]
VALUES
计算一个或一组行。
VALUES ( _expression_ [, ...] ) [, ...]
[ ORDER BY _sort_expression_ [ ASC | DESC | USING _operator_ ] [, ...] ]
[ LIMIT { _count_ | ALL } ]
[ OFFSET _start_ [ ROW | ROWS ] ]
[ FETCH { FIRST | NEXT } [ _count_ ] { ROW | ROWS } ONLY ]
更多内容可以参考手册中的 SQL 语法:http://www.runoob.com/manual/PostgreSQL/sql-syntax.html。















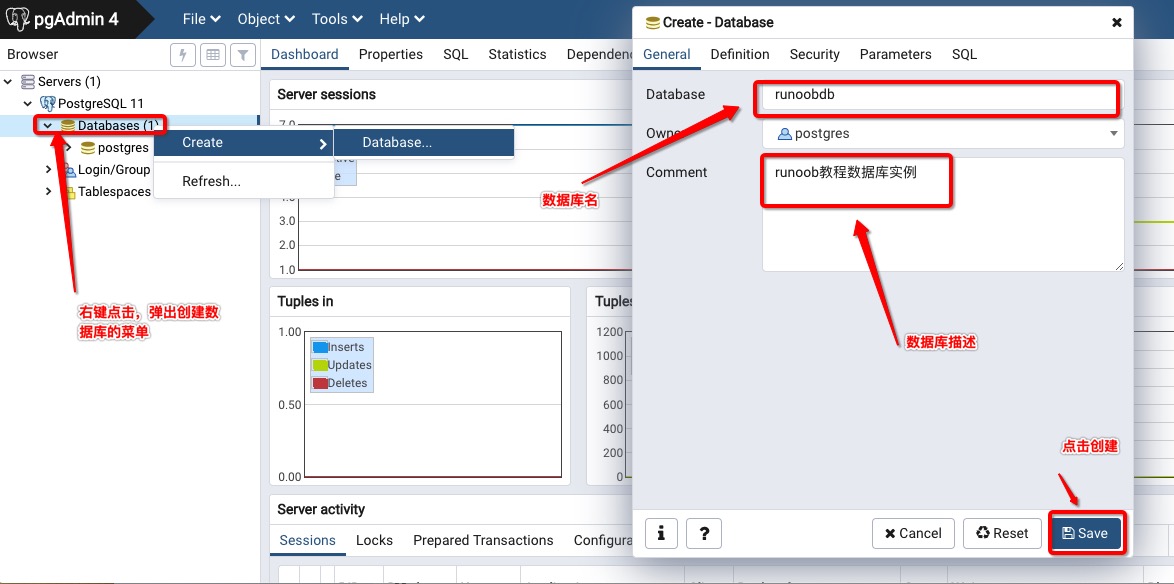
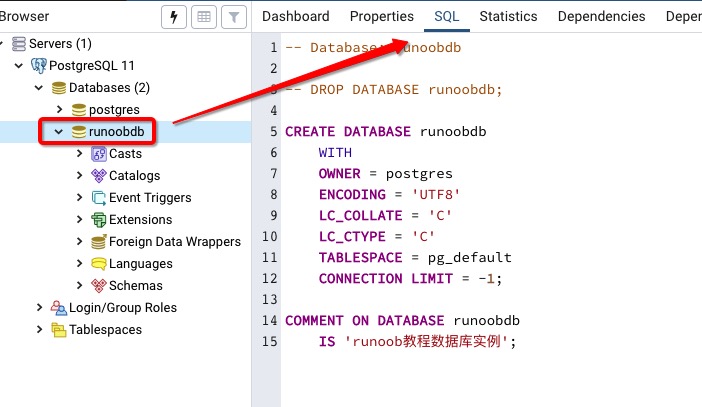
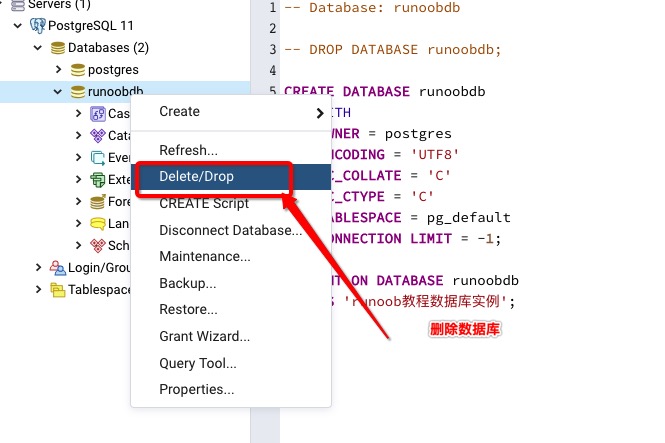
l1nyanm1ng
lin***nming@foxmail.com
给表中某列添加 NOT NULL 约束,语法如下:
alter table ${table_name} alter column ${column_name} set not null;删除表中某列的 NOT NULL 约束,语法如下:
alter table ${table_name} alter column ${column_name} drop not null;l1nyanm1ng
lin***nming@foxmail.com